
Microsoft Fabric giới thiệu Direct Lake, một chế độ lưu trữ đột phá cho các mô hình ngữ nghĩa (semantic models) của Power BI, giải quyết bài toán kinh điển giữa hiệu năng và tính tức thời của dữ liệu. Direct Lake cho phép doanh nghiệp truy vấn trực tiếp trên kho dữ liệu OneLake với tốc độ tương đương chế độ Import, nhưng không cần sao chép dữ liệu hay duy trì các pipeline làm mới (refresh) phức tạp, mở ra khả năng phân tích real-time trên quy mô lớn.
Trong loạt bài viết chuyên sâu về các phương pháp tối ưu Direct Lake, Microsoft đã tập trung phân tích kiến trúc Direct Lake trên SQL được hỗ trợ bởi Fabric Data Warehouse. Đây là giải pháp giúp các đội ngũ phân tích cung cấp báo cáo tương tác nhanh trên các tập dữ liệu ngày càng lớn mà không phải đánh đổi.
Thách thức của BI truyền thống trên dữ liệu lớn
Các đội ngũ phân tích trong nhiều ngành như bán lẻ, y tế, và dịch vụ tài chính đều đối mặt với những thách thức chung khi mở rộng hệ thống BI trên các tập dữ liệu lớn và thay đổi liên tục. Họ thường phải lựa chọn giữa hai phương pháp truyền thống:
- Chế độ Import: Sao chép dữ liệu vào Power BI để đạt hiệu năng truy vấn cao. Tuy nhiên, cách này làm tăng chi phí lưu trữ, tạo ra các bản sao dữ liệu và đòi hỏi quy trình làm mới (refresh) phức tạp, dẫn đến dữ liệu có độ trễ.
- Chế độ DirectQuery: Truy vấn trực tiếp vào nguồn dữ liệu, đảm bảo dữ liệu luôn mới nhất. Tuy nhiên, hiệu năng thường không ổn định và chậm hơn đáng kể khi quy mô dữ liệu và số lượng người dùng đồng thời tăng lên.
Những thách thức này không xuất phát từ giới hạn của kho dữ liệu mà từ cách các mô hình BI tương tác với nó. Direct Lake ra đời để giải quyết sự đánh đổi này.
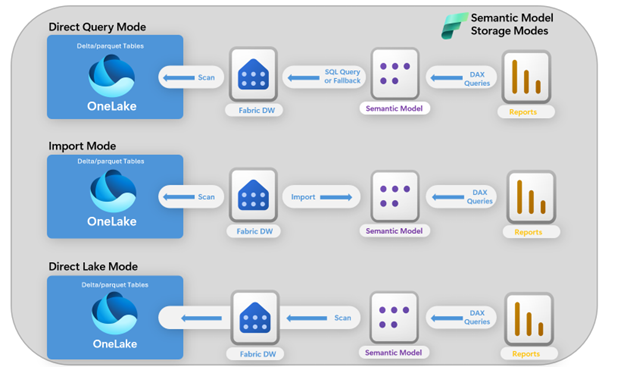
Direct Lake: Giải pháp đột phá của Microsoft Fabric
Direct Lake thay đổi cách các mô hình ngữ nghĩa của Power BI truy cập dữ liệu trong Fabric. Thay vì nhập dữ liệu vào một lớp lưu trữ riêng biệt, Direct Lake thực hiện transcoding (chuyển mã) dữ liệu Delta Parquet được lưu trữ trong OneLake vào bộ nhớ theo yêu cầu. Dữ liệu được tải khi có truy vấn đầu tiên và được giữ lại cho đến khi không hoạt động, có sự thay đổi dữ liệu hoặc do áp lực về bộ nhớ.
Một khi đã nằm trong bộ nhớ, các truy vấn sẽ đạt được hiệu năng tương tự chế độ Import trong khi vẫn duy trì độ tươi mới gần như real-time mà không cần nhân bản dữ liệu. Do hiệu năng phụ thuộc vào bộ nhớ khả dụng, doanh nghiệp có thể lựa chọn gói SKU của Fabric phù hợp dựa trên kích thước và đặc điểm workload của mô hình.
Kiến trúc và cách hoạt động của Direct Lake trên SQL
Các mô hình ngữ nghĩa Power BI kết nối với SQL analytics endpoint của Fabric Data Warehouse (DW) và đọc các bảng Delta từ OneLake bằng chế độ Direct Lake. Dữ liệu được nạp vào bộ nhớ từ các file Delta Parquet. Các bảng Delta này vẫn có thể được truy cập thông qua SQL analytics endpoint cho các tác vụ chuyển đổi dữ liệu, các kịch bản composite model, hoặc khi Direct Lake phải sử dụng fallback (cơ chế dự phòng) về chế độ DirectQuery.
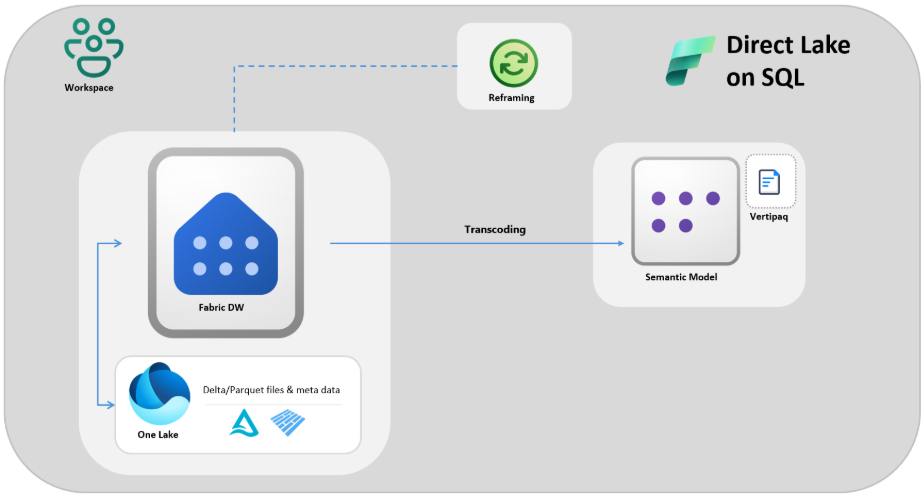
Microsoft lưu ý rằng Fabric cung cấp hai phiên bản Direct Lake: Direct Lake trên SQL và Direct Lake trên OneLake. Bài viết này tập trung vào phiên bản trên SQL, vốn vẫn được sử dụng rộng rãi và là lựa chọn phù hợp khi cần áp dụng bảo mật dựa trên SQL ở cấp độ kho dữ liệu. Tuy nhiên, Direct Lake trên OneLake là con đường chiến lược dài hạn và sẽ nhận được nhiều đầu tư hơn trong tương lai, cho phép kết nối trực tiếp đến các bảng Delta trong OneLake mà không cần thông qua SQL endpoint.
Lợi ích khi kết hợp Direct Lake với Fabric Data Warehouse
Không giống như Direct Lake trên Lakehouse yêu cầu quản lý thủ công các tác vụ tối ưu hóa, Fabric Data Warehouse tự động hóa các cơ chế này để đảm bảo các workload Direct Lake luôn đạt hiệu năng cao và tuân thủ các giới hạn:
- Hợp nhất tệp (File Consolidation): Tự động gộp các tệp parquet nhỏ thành kích thước tối ưu (100 MB – 1 GB), ngăn chặn tình trạng phân mảnh tệp làm giảm hiệu năng.
- Quản lý thống kê: Luôn cập nhật số liệu thống kê để bộ tối ưu hóa truy vấn (Query Optimizer) tạo ra các kế hoạch truy vấn hiệu quả mà không cần can thiệp thủ công.
- Mặc định V-Order: Tự động áp dụng V-Order cho tất cả các bảng để tối ưu hóa việc đọc. V-Order sắp xếp lại dữ liệu parquet để cải thiện khả năng nén và hiệu năng truy vấn cho quá trình transcoding của Direct Lake.
- Giảm chi phí vận hành: Các kỹ sư dữ liệu có thể tập trung vào mô hình hóa dữ liệu và logic nghiệp vụ thay vì phải lên lịch các kịch bản bảo trì hay giám sát phân mảnh tệp.
- Bảo vệ giới hạn (Guardrail Protection): Bằng cách tự động duy trì kích thước và số lượng tệp tối ưu, Fabric DW giảm nguy cơ Direct Lake phải fallback về DirectQuery do vượt quá giới hạn tệp parquet.
- Phân cụm dữ liệu (Data Clustering): Kỹ thuật này tổ chức và lưu trữ dữ liệu dựa trên sự tương đồng, giúp cải thiện hiệu năng truy vấn và giảm chi phí truy cập tính toán và lưu trữ.
Các phương pháp tối ưu để khai thác tối đa hiệu quả
Để đạt được hiệu suất tốt nhất, Microsoft khuyến nghị các đội ngũ kỹ thuật nên tuân thủ các nguyên tắc thiết kế sau:
- Tối ưu hóa Cardinality: Đây là yếu tố quan trọng nhất đối với hiệu năng của Direct Lake. Các cột có cardinality cao (số lượng giá trị duy nhất lớn) như ID giao dịch tiêu tốn nhiều bộ nhớ hơn. Doanh nghiệp nên sử dụng khóa thay thế dạng số, chuyển các cột mô tả có cardinality cao sang bảng chiều (dimension tables).
- Xây dựng mô hình Star Schema tập trung: Giữ cho các bảng gọn gàng, chỉ chứa các cột cần thiết cho báo cáo. Các bảng fact chỉ nên chứa các số đo và khóa ngoại.
- Lưu ý về cơ chế Fallback về DirectQuery: Direct Lake sẽ chuyển sang chế độ DirectQuery khi mô hình vượt quá giới hạn dung lượng, sử dụng SQL view làm nguồn, hoặc khi phát hiện bảo mật dựa trên SQL. Doanh nghiệp nên sử dụng bảng gốc thay vì view và áp dụng Row-level security (RLS) ở lớp mô hình ngữ nghĩa để tận dụng hiệu năng in-memory.
- Hiểu về trạng thái Cache: Hiệu năng của Direct Lake thay đổi tùy thuộc vào trạng thái cache của dữ liệu (Cold, Warm, Hot). Việc hiểu rõ các trạng thái này giúp đặt kỳ vọng thực tế và định hướng các chiến lược tối ưu hóa.
Tác động thực tiễn và công cụ hỗ trợ
Các tổ chức áp dụng phương pháp tối ưu Direct Lake với Fabric Data Warehouse đã ghi nhận những lợi ích vận hành đáng kể:
- Hiệu năng truy vấn tương đương chế độ Import mà không cần chi phí làm mới theo lịch.
- Dữ liệu real-time thay thế cho dữ liệu có độ trễ từ các chu kỳ làm mới.
- Loại bỏ các sự cố liên quan đến việc làm mới dữ liệu thất bại.
- Kiến trúc đơn giản hóa bằng cách hợp nhất các mô hình.
- Tối ưu hóa lưu trữ tự động bởi Fabric DW, loại bỏ việc bảo trì tệp thủ công.
Để hỗ trợ các đội ngũ kỹ thuật, Microsoft và cộng đồng cung cấp các công cụ như Delta Analyzer, VertiPaq Analyzer (thông qua DAX Studio) và Semantic Link Labs để giám sát, phân tích và tối ưu hóa hiệu năng của các mô hình Direct Lake.
Để bắt đầu, doanh nghiệp có thể triển khai Direct Lake cho một trường hợp sử dụng có tác động cao, đo lường kết quả và sau đó mở rộng ra toàn tổ chức. Đây là một bước tiến quan trọng giúp các doanh nghiệp chuyển đổi kiến trúc phân tích của mình, hướng tới một nền tảng dữ liệu nhanh hơn, hiệu quả hơn và dễ quản lý hơn.