Ngày 27/05/2026, Microsoft Fabric đã giới thiệu Incremental Liquid Clustering, một tính năng đột phá giúp giảm đáng kể chi phí và thời gian cho việc tổ chức dữ liệu trong môi trường lakehouse. Giải pháp này giải quyết thách thức lớn khi việc duy trì layout dữ liệu trở nên tốn kém khi quy mô bảng tăng lên, giúp doanh nghiệp tối ưu hóa chi phí vận hành mà không ảnh hưởng đến hiệu năng truy vấn.
Thách thức từ cơ chế clustering truyền thống
Liquid Clustering giúp giảm chi phí truy vấn bằng cách sắp xếp dữ liệu để các query chỉ cần đọc những file cần thiết. Tuy nhiên, việc duy trì layout này lại tốn kém: mỗi lệnh OPTIMIZE đều tiêu tốn tài nguyên tính toán để ghi lại file.
Thuật toán tiêu chuẩn từ mã nguồn mở Delta Lake ghi lại toàn bộ dữ liệu trong các nhóm file đã được cluster mỗi khi chạy OPTIMIZE, bất kể các file đó đã được sắp xếp tốt hay chưa. Ví dụ, việc thêm 1 KB dữ liệu vào một bảng 99 GB cũng sẽ kích hoạt việc ghi lại toàn bộ hơn 99 GB dữ liệu đó. Điều này khiến chi phí clustering tăng tuyến tính theo kích thước của bảng chứ không phải theo lượng dữ liệu mới, làm cho việc duy trì cluster cho các bảng lớn trở nên không hiệu quả.
Incremental Liquid Clustering: Tối ưu thông minh và tiết kiệm
Tính năng Incremental Liquid Clustering của Microsoft Fabric đã khắc phục được sự mất cân bằng này: giữ nguyên hiệu năng truy vấn nhưng với chi phí duy trì chỉ bằng một phần nhỏ.
Thay vì ghi lại tất cả mọi thứ, lệnh OPTIMIZE giờ đây chỉ xác định và xử lý các file thực sự cần clustering, bao gồm:
- File chưa được cluster: Dữ liệu mới được thêm vào mà không có metadata về clustering.
- File nhỏ: Các file có kích thước dưới ngưỡng mục tiêu cần được gộp lại.
- File có vector xóa: Các file có số lượng bản ghi bị xóa vượt quá ngưỡng dọn dẹp.
Các file đã được cluster tốt và có kích thước phù hợp sẽ được bỏ qua hoàn toàn. Dữ liệu mới được định tuyến vào các nhóm file đã cluster sẵn, duy trì tính liên tục của layout mà không cần ghi lại dữ liệu đã ở đúng vị trí. Kết quả là một hoạt động clustering có thời gian gần như không đổi, chỉ phụ thuộc vào kích thước dữ liệu mới chứ không phải kích thước của toàn bộ bảng.
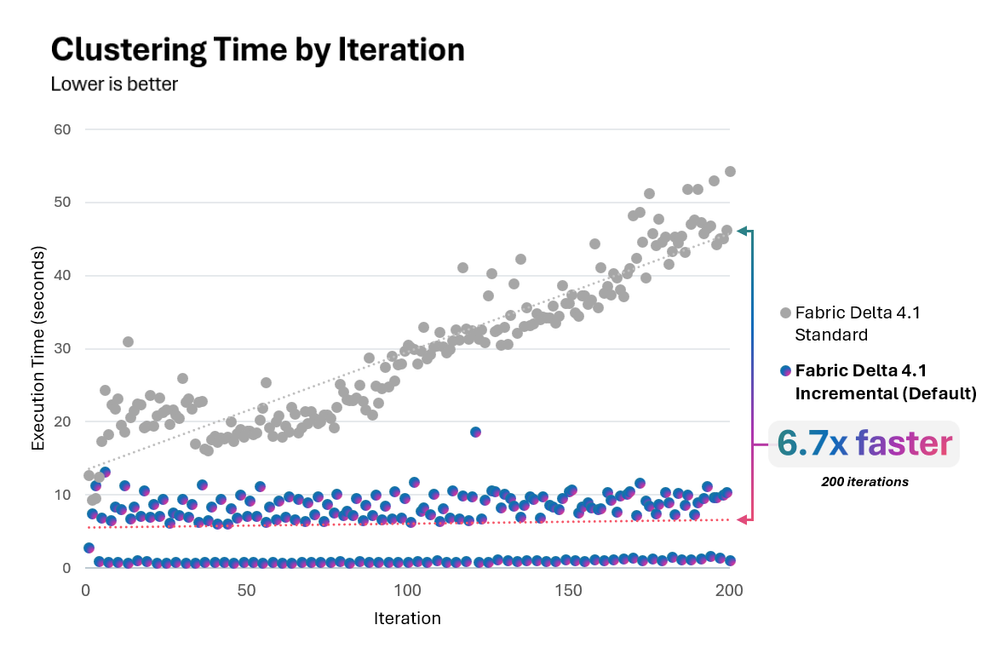
Biểu đồ trên cho thấy thời gian clustering của thuật toán tiêu chuẩn (Standard) tăng tuyến tính theo kích thước bảng, trong khi chế độ gia tăng (Incremental) duy trì ở mức ổn định.
Tự động duy trì chất lượng với Auto Reclustering
Incremental Liquid Clustering còn bao gồm tính năng Auto Reclustering. Thuật toán sẽ tự động xác định các cluster có file bị chồng chéo và chỉ cluster lại các file bị suy giảm chất lượng khi vượt ngưỡng cho phép, giúp chất lượng dữ liệu luôn cao mà không cần can thiệp thủ công.
Hiệu năng vượt trội qua các kịch bản thực tế
Microsoft đã thực hiện benchmark trên ba kịch bản workload phổ biến:
- Streaming Ingest: Các lượt ghi nhỏ liên tục, dữ liệu mới không chồng chéo với bản ghi hiện có (ví dụ: dữ liệu IoT, clickstream).
- Analytics Table: Dữ liệu mới chồng chéo hoàn toàn với bản ghi hiện có (ví dụ: bảng dimension).
- ETL Pipeline: Các hoạt động
MERGEnơi dữ liệu đến chồng chéo một phần (ví dụ: CDC feeds, cập nhật đơn hàng).
Kết quả cho thấy tốc độ cải thiện đáng kể:
- Streaming Ingest: Nhanh hơn 8.9 lần.
- Analytics Table: Nhanh hơn 5.5 lần.
- ETL Pipeline: Nhanh hơn 4.9 lần.
Đáng chú ý, hiệu năng của thuật toán tiêu chuẩn suy giảm mạnh khi dữ liệu tăng lên, trong khi Incremental Liquid Clustering giữ được sự ổn định.
So sánh với các giải pháp khác trên thị trường
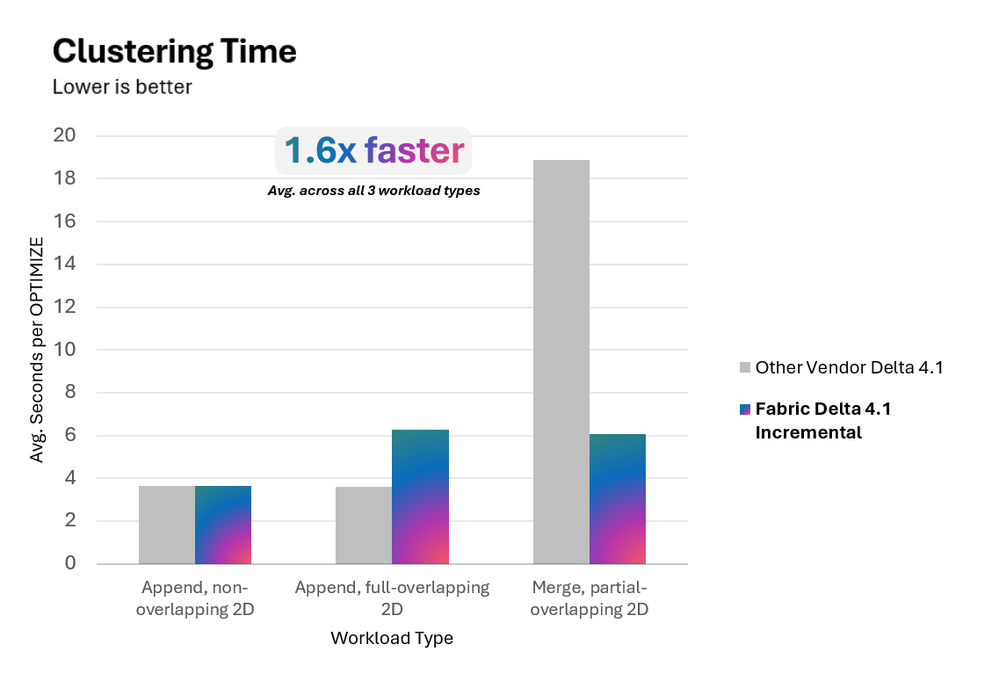
Khi so sánh với một giải pháp liquid clustering khác của đối thủ, Incremental Liquid Clustering của Fabric cho kết quả ấn tượng:
- Tốc độ clustering trung bình nhanh hơn 1.6 lần.
- Lượng file cần quét cho các truy vấn chọn lọc ít hơn 11%.
- Với các workload nặng về
MERGE(mô hình phổ biến nhất của người dùng Apache Spark), Fabric nhanh hơn hơn 3 lần.
Mã nguồn để tái tạo các benchmark này được công bố trên GitHub.
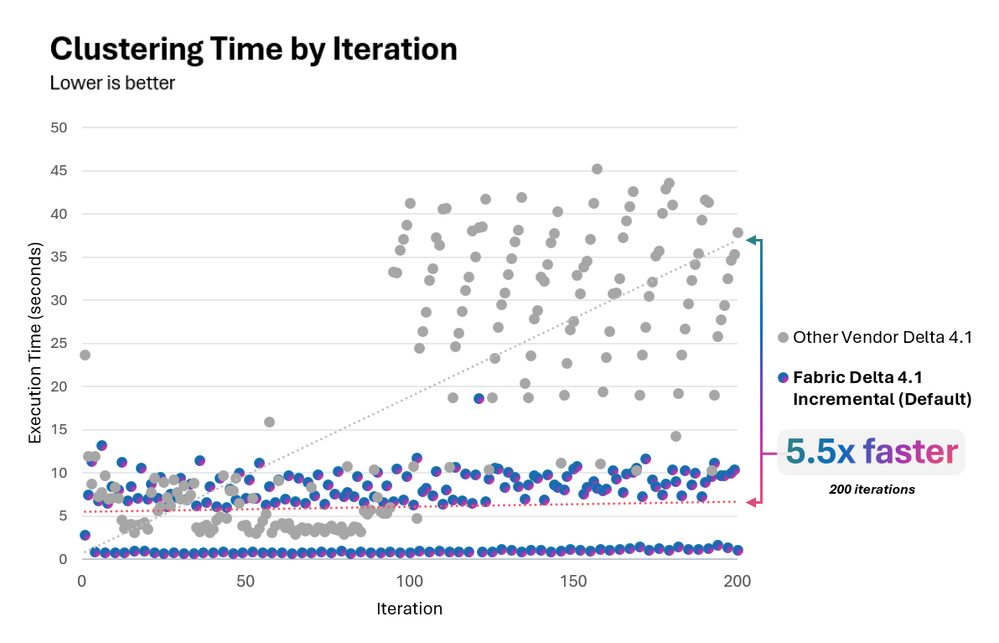
Thời gian clustering
Đối với các workload MERGE, thời gian clustering của đối thủ suy giảm đáng kể sau khoảng 100 vòng lặp, trong khi Fabric vẫn duy trì tốc độ nhanh và ổn định.
Chất lượng bỏ qua file (File skipping)
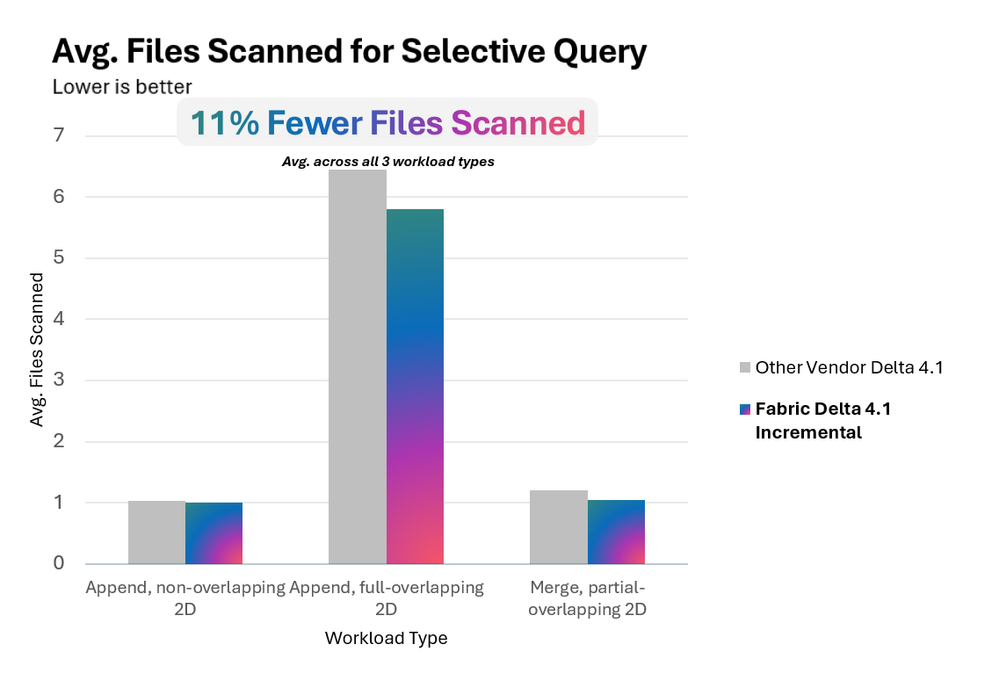
Fabric đạt được khả năng file skipping (bỏ qua file không liên quan khi truy vấn) tương đương hoặc tốt hơn. Đặc biệt với workload ghi chồng chéo hoàn toàn, Fabric quét ít hơn 11% số file cho mỗi truy vấn, cho thấy khả năng tạo ra layout dữ liệu chất lượng cao hơn.
Lợi ích cho doanh nghiệp và tính sẵn sàng
Incremental Liquid Clustering đã có sẵn trong Fabric Runtime 2.0 với Delta 4.1 và Spark 4.1, và được bật mặc định. Doanh nghiệp chỉ cần chạy lệnh OPTIMIZE trên các bảng Liquid Clustered để thuật toán mới tự động được áp dụng.
Các lợi ích chính bao gồm:
- Pipeline streaming và gần thời gian thực: Lệnh
OPTIMIZEchạy trong vài giây thay vì vài phút, đảm bảo SLA. - Pipeline ETL và batch: Giảm đáng kể chi phí tính toán cho việc tối ưu hóa sau khi tải dữ liệu.
- Bảng phân tích: Hiệu năng truy vấn cao được duy trì tự động khi dữ liệu thay đổi, không cần tinh chỉnh thủ công.
Đây là một bước tiến lớn hướng tới một lakehouse có khả năng tự tối ưu hóa, loại bỏ sự đánh đổi giữa chất lượng và chi phí clustering. Để tìm hiểu thêm, doanh nghiệp có thể tham khảo tài liệu chính thức từ Microsoft.