Ngày 18/05/2026, Microsoft đã công bố tính năng Resource Profiles (bản Preview) cho Microsoft Fabric Data Engineering. Tính năng này giúp doanh nghiệp tự động tối ưu hóa cấu hình Apache Spark, giải quyết bài toán cân bằng giữa chi phí, hiệu năng và tốc độ xử lý cho các workload dữ liệu đa dạng mà không cần tinh chỉnh thủ công.
Các đội ngũ kỹ sư dữ liệu hiện đại luôn chịu áp lực phải cung cấp các pipeline nhanh hơn, chi phí thấp hơn và hiệu năng ổn định, trong khi phải xử lý các workload ngày càng đa dạng. Trên thực tế, một cấu hình Spark duy nhất cho mọi tác vụ hiếm khi hoạt động hiệu quả. Các pipeline nhập dữ liệu, các job chuyển đổi, phân tích tương tác và truy vấn BI đều đặt ra những yêu cầu rất khác nhau về tài nguyên tính toán.
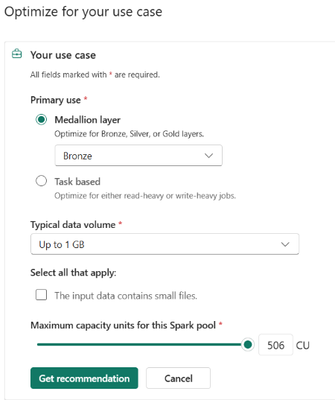
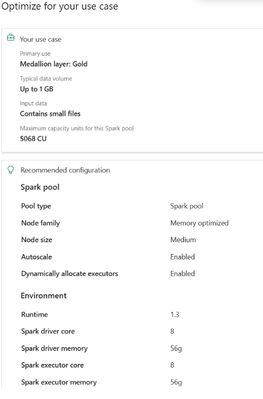
Resource Profiles là gì?
Resource Profiles là các hồ sơ tài nguyên tính toán được cấu hình sẵn, nhận biết được loại workload để tối ưu hóa các thiết lập môi trường Spark dựa trên cách dữ liệu được đọc, ghi và sử dụng. Thay vì phải tinh chỉnh hàng chục thuộc tính của Spark, người dùng chỉ cần chọn một hồ sơ phù hợp với mô hình workload của mình và Microsoft Fabric sẽ tự động áp dụng cấu hình tối ưu.
Hiện tại, Fabric Data Engineering hỗ trợ các hồ sơ sau:
- Write-heavy: Tối ưu cho các workload nhập và chuyển đổi dữ liệu với thông lượng cao.
- Read-heavy for Spark: Tối ưu cho các tác vụ đọc dữ liệu thường xuyên bằng Spark và các truy vấn tương tác.
- Read-heavy for Power BI: Tối ưu cho việc sử dụng trong BI và SQL trên các bảng Delta.
Mỗi hồ sơ tổng hợp các thiết lập tốt nhất được đúc kết từ các workload thực tế và kiểm thử nội bộ, giúp doanh nghiệp đạt được hiệu năng ổn định ngay từ đầu.
Tại sao doanh nghiệp cần Resource Profiles?
Một thách thức chung mà các khách hàng doanh nghiệp gặp phải khi đánh giá Microsoft Fabric là khó khăn trong việc đạt được hiệu quả chi phí-hiệu năng nhất quán khi chạy các workload Spark đa dạng trên một bộ cấu hình duy nhất.
Các job nhập dữ liệu (write-heavy) cần thông lượng và khả năng song song hóa cao. Trong khi đó, các workload tối ưu cho việc đọc (read-optimized) lại yêu cầu độ trễ thấp để phục vụ phân tích, SQL và Power BI. Việc cân bằng các yêu cầu này một cách thủ công thường dẫn đến việc phải thử và sai, tăng chi phí vận hành và cho kết quả không tối ưu.
Resource Profiles giải quyết trực tiếp vấn đề này bằng cách cho phép người dùng khai báo mục tiêu công việc, và để Fabric tự xử lý việc tối ưu hóa tài nguyên tính toán.
Tối ưu cho kiến trúc Medallion và các tác vụ chuyên biệt
Resource Profiles phù hợp một cách tự nhiên với kiến trúc dữ liệu Medallion hiện đại:
- Lớp Bronze: Các job nhập dữ liệu được hưởng lợi từ hồ sơ write-heavy với khả năng song song hóa và bố cục file được tối ưu.
- Lớp Silver: Các job chuyển đổi có thể sử dụng hồ sơ cân bằng hoặc read-heavy cho Spark tùy thuộc vào mô hình truy cập.
- Lớp Gold: Các kịch bản sử dụng dữ liệu trong Power BI, SQL Warehouse và phân tích tương tác sẽ được hưởng lợi từ các hồ sơ read-optimized.
Bằng cách điều chỉnh hành vi tính toán cho từng giai đoạn của vòng đời dữ liệu, các đội ngũ có thể đạt được SLA tốt hơn, pipeline nhanh hơn và giảm biến động chi phí mà không cần tinh chỉnh phức tạp.
Hiệu năng mặc định và khả năng kiểm soát linh hoạt
Resource Profiles được thiết kế để đảm bảo an toàn, minh bạch và linh hoạt:
- Các workspace mới trên Fabric sẽ mặc định sử dụng hồ sơ write-optimized, đảm bảo hiệu năng nhập dữ liệu mạnh mẽ ngay từ ngày đầu tiên.
- Các hồ sơ có thể được cấu hình ở cấp độ môi trường và được ghi đè linh hoạt khi cần thiết.
- Các workload hiện có không bị gián đoạn, các đội ngũ vẫn có toàn quyền kiểm soát thời điểm và cách thức áp dụng các hồ sơ.
Cách tiếp cận này mang lại hiệu năng mặc định trong khi vẫn duy trì khả năng kiểm soát mà các đội ngũ doanh nghiệp mong đợi.
Các bước tiếp theo
Tính năng Resource Profiles đã có sẵn ở dạng Preview trong Microsoft Fabric Data Engineering. Doanh nghiệp có thể bắt đầu bằng cách chọn một hồ sơ trong phần cài đặt Môi trường (Environment) và trải nghiệm sự khác biệt trong lần chạy pipeline tiếp theo.
Để có hướng dẫn chi tiết, người dùng có thể tham khảo tài liệu Data Engineering của Microsoft Fabric.